
In v2.5.90 we introduced the "Confidentiality Score". This score has been designed to support the assignment of vulnerabilities to components. NVD's JSON4-CVE format, the still current version, CVEs carry information about the products they belong to resp. which are impacted by them. These products currently are referred to using CPEs, the Common Platform Enumeration IDs. NVD maintains a so called CPE-dictionnairy, where it lists all CPEs (here v2.3 gzip).
Identifying the correct component
However, this enumeration has been developed with products in the designer's mind. Thus it mainly consists of a string combining different values such vendor organisation, product line or platform, e.g. windows. This is well suited for match making with a corporate asset inventory, e.g. microsoft:internet_explorer:10.0.1, but has certain limits when it comes to development components or open source projects: The definition of an organisation or vendor, or even the product may be difficult, when describing a three source files comprising bundle, that has bee developed by a single person publishing it on Github. And even if it some definition has been made, will the second incident use the same way to identify the previously made up term?
In addition to that, there is no uniqueness amongst names. The search for the word "core" returns 382,000+ hits for repositories containing "core" in the name, the first 25 even using "core" as unique identifier.
But not enough, projects get stalled and forks emerge, still containing the same codebase. Projects are released into different packages and package managers, changing package names, organisations, etc.
All this leads to some difficulties in assigning CVEs back to the corresponding open source components.
Finding specific Versions
Thus exact matching of version numbers is not always trivial. CPEs may contain a version string, e.g. `vendor:product:10.0.1.` This describes an issue specific to the exact version 10.0.1. Often, vulnerabilities are not limited to a specific version. Sometimes all version prior to a specific version or only a one or more specific ranges are impacted.
The JSON4-format offers two options to define ranges: either by enumeration or through configurations. While the first simply enumerates the impacted versions, the latter allows the definition of ranges, e.g. "start: 2.3.15" , "end: 2.3.36" AND "start: 3.1.20", "end: 3.1.22". Which form is used depends on the preferences of the CNA, the CVE numbering authority or the MITRE supporter, who is about tho add this data.
Further information in the description
Additional information sometimes can be found in the description. This will be fine for any security researcher who is studying the vulnerability to make his own assumptions, look into the references and understand the impact. It is not enough to make a proper and sound technical match making. We started a project, that is trying to assess the description and derive some additional value from that data by applying Natural Language Processing. The first results are encouraging but not yet stunning (75-85% success). We will report in our blog (DE/EN).
NVD understood this to be an issue and extended the JSON5, which has been announced for last summer, with options to use purls and repo-links to simplify package matching. However, before this will not be applied to the whole dataset, Processing still requires match making based on insufficient values.
Match making
To make a long story short: It is not always simple to match a component based on its package name with existing CVE information. Depending on the degree of sensitivity you apply, you will get more or less false positives. But in the same time accepting more false positives will reduce the probability to miss a potentially important but weak match.
To overcome the dilemma, we have introduced the Confidentiality Score. This new score describes the confidentiality with which the match has been made. Depending on what has been matched, the score will get different values. A high score matched more aspects than a lower. After experimenting we came up with 3 levels: High medium and low, whereby the
- HIGH:
We have a clear match. Several indicators (org, product, vendor, version, reference, etc.) allow a sound match. You may bet on this. - MEDIUM:
At least two indicators match. Thus it is most likely correct, but there is light chance of a mismatch. - LOW:
In this case a match has been made, but only on one indicator, typically product. Thus despite the match, it may still be a false positive.
You now may use the Confidentiality setting at module level to see the impact, an alternative selection will have. We recommend to start working with the medium level and raise it towards the release. You may receive important indications of potential impact working with the medium level.

Use the "All" selection, when you want to review new components. This will help to get a better impression of potential issues. During the standard work, we recommend to use the medium setting. High makes sense, when you want to progress fast. This is reducing noise. But beware to wake up a few days before launch date with a huge list of untouched medium cases.
To work with the high impact vulnerabilities, select the vulnerabilities focus (shield) next to the status filters and filter away all green components. Immediately the list will only contain entries with vulnerabilities. Now you may switch between the different confidentiality scores using the selector left from the shield button. According to the
PLEASE NOTE: Showing no known vulnerabilities in the "High" selection, does not guarantee that there are no vulnerabilities. It just says's that there could no vulnerability associated with high confidence. We strongly encourage to review at least the matches with medium confidentiality.
Hint for hidden vulnerabilities
Even if you select a high confidentiality in the module indicator (center), you will see a hint in individual components, given there are lower confidentiality level matches.
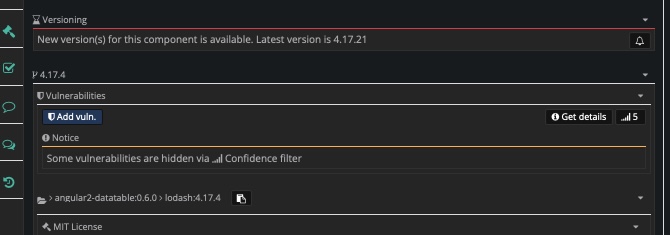
You then may switch the filter for this particular component only clicking on the confidentiality filter button on the outer right side, behind the "get details" button. This will switch the filter for the particular component only and therefor allow you to change the dsiplay for a particular component only.
While the above picture shows the situation for the component lodash on "high confidence" selection above, lowering the filter will unveil a handful of relevant matches.
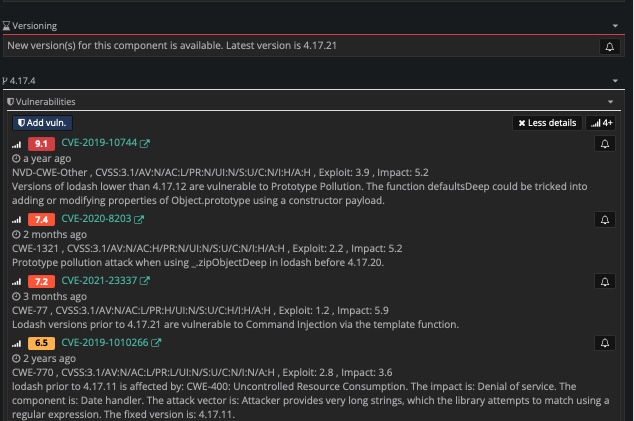
The reason why this matching is not on a high confidentiality is due to the single match.
We are continuously monitoring the quality of our matching. If you feel certain confidentialities not being correctly assigned, feel free to request a change through our support. We will notify the remarks and add the, into our regular review rounds.
Comments
0 comments
Article is closed for comments.