
TrustSource provides a platform to cope with all tasks of open source compliance management. The capabilities required therefor are clearly analyzed and discussed in the concept section. An overview of the capabilities required to cope with this process can be found in the Open Chain Tooling Working Group Capabilities Map or this presentation. The latest public version can be found here
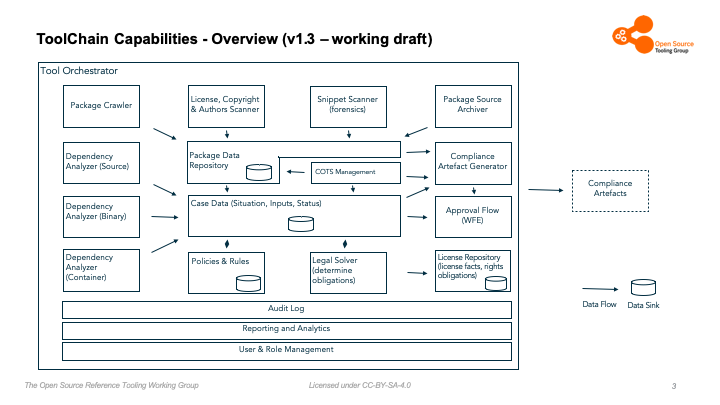
TrustSource has choosen the following architecture to comply with these requirements:
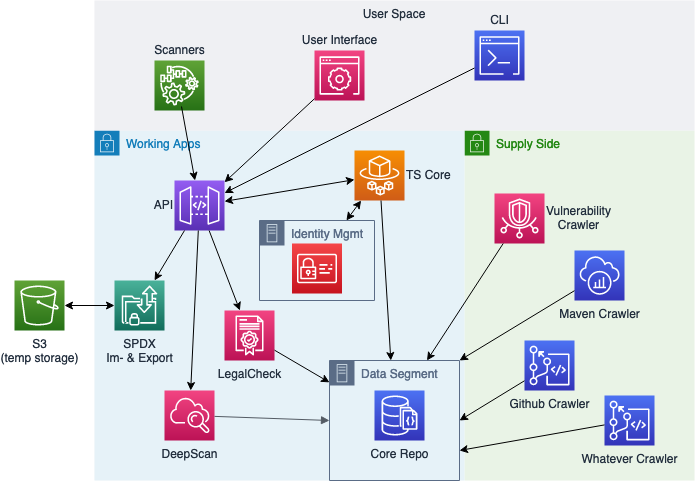
Please find here a mapping of the capabilities to the TrustSource service components:
Scanners:
One of the key capabilities in compliance is to determine the composition of the software you want to make compliant. There are four different approaches to determine the composition of a software, depending on the stage in the lifecycle respectively the available information:
a) Look at the source code repository (Repository scan)
b) Look at what is assembled during build time (CI/CD-scan)
c) Look at a dockerfile or image (Docker scan)
d) Look at a binary (Binary scan)
In general it is useful to start assessing software as early as possible. The earlier you discover unwanted parts or components, the less time it requires to replace them. This is why we highly recommend to use the CI/CD integration even on the developers desktop to assess and determine the components used. However, sometimes you might not have access to the corresponding information or sources.
To cope with complete repository scans, we have provided DeepScan (see below).
To handle assessments during build time, TrustSource has provided a plethora of integrations with package managers for most of the commonly used programming languages and tools. See the integration page for more details on the specific integration.
To cope with dockerfiles, there are two cool open source solutions available: anchore engine and tern. We are currently assessing anchore to see how to integrate their analysis output into our Scan-API.
To assess binary files, TrustSource currently does not provide any capability. But we are looking at BANG (binary analysis next generation) as a suitable fit in that segment.
Component-Crawlers:
Knowing what the composition is only half the story. Knowing something about the component is essential to determine suitability or how to proceed. As there are so many programming languages and even more places to publish your code, it is a massive amount of work to collect all information. Just to get a grip on it, the Software heritage foundation has the aim to build a global archive of open source software. Started a few years ago, they meanwhile host over 2 billion artefacts. Git hub counts 40 million something repositories, all active repositories producing new versions every few days. Each version might be composed differently.
These few figures shall illustrate the vast amount of data that is to be managed. Finding a particular component with a specific version and identify its meta data for further documentation is the task these crawlers complete. In our managed service we have the approach to crawler several sources and collect all data that is available. So our database comprises at the writing of this over 17 million components, and more than 500 million dependencies growing up to 300 GB and keeps growing.
To prevent unlimited multiplication, the crawlers in the community edition are designed to work pull based. They only lookup components entering the db. They will search several locations and report data into the repository for further processing.
Depending on your programming goals, you might want to use only a subset of crawlers. Review the ts-crawlers repository for more details on crawlers and how to adjust.
Vulnerability-Crawlers:
Given you have a clear understanding of all the components in your software, it makes a lot of sense to review these for known vulnerabilities. To do this, you require a repository of vulnerability information which is continuously updated so it will be possible to search it for every new component and assign known issues immediately.
Unfortunately it is not that simple. To learn more about the issues related to assigning vulnerabilities to components, read this article. To cope with some of the issues, the maintenance of matching tables are a useful tool. Some others may be overcome by providing additional matching criteria or assessing the informational environment.
The given implementation provides two types of search.
- a) Searching for known vulnerabilities associated to a particular component
- b) Searching from a new or updated vulnerability the projects that use affected components
While the first isn't trivial, it is a common use case and has a well performing implementation in the OWASP dependency scanner. An older version of this has been used in the vulnerability crawler implementation provided in the public version of this service.
Whenever new vulnerabilities enter the system, all existing scans will be assessed for potential matches. So even if a Tomcat 8 from 5 years ago get a new vulnerability assigned,
TrustSource Core:
This is the heart of the system. It takes the responsibility of user management (together with the additional Identity Management Service) roles, workflows, orchestration (mainly triggered by UI actions), reports, compliance artefacts generation, componante management and repository access, projects and legal case data management, administrational tasks, etc.
Comparing the requirements of the OC Tooling WG Capability Model, our core combines the following capabilities:
- Policy & rules management
Providing OS policy (inbound & outbound) as well as support in rolling it out or making changes visible to users. - Case data management
Freeze the circumstances defined for a particular component and under which the legal approval has been granted - Approval flow
Clearly define which modules / components in which version shall be approved for which case data. Provide an integrated perspective (legal, security, documentation, etc.) and document approvals or rejections. Automated generation of documentations allows to trigger approvals through API and gain insights on the likeliness of acceptance allowing for automated decisions on further deployments. - Compliance artefact generator
Generate Bill of Materials, SOUP-lists or Notice files based on the current state of the module/project. Receive notice file stubs with open fields for missing information so that you may focus on the missing bits. - Reporting and analytics
A huge amount of reports is available to support your day to day tasks. The traffic light indicators direct you where to drill deeper. Wnat to know which projects are affected by a particular CVE? Need to see what licenses appear most? Want to see the open issues in a particular project? - Audit log
Record all relevant changes (muting of vulnerabilities, changes in component state or case data, etc.) for sustainable, correct behavior of all participants. - COTS management
Especially for medical documentation the management of Common of the shelf components is a requirements. Together with medical device manufacturers developed, the COTS management enriches the component repository to cope with the documentation requirements of SOUP-lists.
Within v1.9 we have added the very powerful feature "linked modules". This allows you to use projects from your own code base as components within other projects. Thus if your team is creating an update or a new release, the users will be notified. The same in case of vulnerabilities being identified within the component. So even if the project owner himself is not concerned by the vulnerability due to his usage scenario, the consumer of his component might be. The linked module propagates this information across the teams.
You will find the TS-Core including the UI on github. It can be operated in a Docker environment. The core requires a mongo database as a repository. Find more information at Github or in our setup section.
LegalCheck Service:
This is a real differentiator of TrustSource. The LegalCheck-Service allows to determine the legal obligations resulting from the set of components, their modification state, linkage type, the commercial conditions and its distribution, even if motivated only by architectural position (e.g. frontend library)
Core collects all data and throws it at the LegalCheck (Case data, components list as well as their state and meta data) and returns a list of obligations by component that are required to comply with all licenses under the given circumstances.
Thus it becomes possible even for legally unskilled staff to understand what is required. Together with the compliance artefact generators in the core component, this allows to generate stubs of compliance documents such as notice files using all available information form the repository and determine the missing parts.
Due to the Core providing a log of changes on the case data, it will always be possible to review the circumstances that led to a compliance declaration at a certain point in time. It is also possible to review the impact of changes concerning the circumstances or simulate additional use cases.
The LegalCheck-engine is using a solver and a fact base. The fact base is provided by lawyers (we have engaged and financed) having assessed hundreds of licenses for relevant aspects. The solver has been provided with a grammar containing the rules to determine the impact of a license in a given case. This in combination with the audit trails created from the UI and API access provide a sound framework for compliance.
Assess LegalCheck on Github for more details.
DeepScan Service:
As stated above, one of the methods to assess software is a repository analysis. We do not prefer this method as it does really provide the correct picture of what your solution will consist of. CI/CD-based SCA is much more accurate, especially in "package" oriented languages like Python, Java or JavaScript.
However, there are also many C, C++ or C# developments. Starting to provide Conan the C-world is slowly about to to move into this direction as well. But it will take quiet a while. Thus repository based approaches give more insight for this sort of environments.
In the latest version, DeepScan has the ability to compare scans and therefor understand changes in repositories or discover copycats. In C-based programming re-use sometimes occurs by copying single files or parts of the repository tree. DeepScan is able to identify such situations across all scanned repositories in your company.
But there is also another case. Given you plan to use an open source project in your organization / solution and want to get a sound understanding of the consequences, it is beneficial to screen the complete code before just relying on the declared license. It happens more than often, that even inside the repository you will find many undeclared licenses. If there is a GPL, EPL or Cecil undercover, the awakening might be uncomfortable.
And even if there are no additional licenses, it will be beneficial to have a service collecting all author and copyright statements, in case you are required to put then on a notice file later. There is a great solution called ScanCode from nexB which does a great job om identifying the copyright statements. For parts of the job, we are also integrating ScanCode. In DeepScan you have the choice to switch the copyright processing on or off to save time in case you do not require it.
Due to its very compute intense operations, DeepScan requires a very scalable base. we commend to operate it on a Kubernetes or Docker Swarm cluster. There is a free version for use through UI available, so you might test it right away. As a TrustSource SaaS subscriber you will have unlimited access even through API. A version for your local use may be found at Github.
There is another open source solution which is suitable for a repository scans that is called Fossology. Originally developed by HP it became a project of the Linux foundation and is now heavily used.
SPDX Im- & Export Service:
As mentioned before we intend to rely on several other open source solutions to complete the stack of open source compliance management solutions. Whenever data travels between systems a common format makes a lot of sense. The Software Package Data Exchange (SPDX) has been designed to cope with this challenge.
Despite being not the youngest anymore, the standard still is somewhat volatile. The v2.1 brought some incompatible changes to v2.0 implementations (e.g. <File>-tag changed to <hasFile>) and while 2.2 still is under construction, v3.0 already has a branch. Too much change is not good for a standard, even if some improvements are required. Despite the changes, it remains the only sound concept that has the potential to cope with the requirements of compliance data exchange. This is why we are supporting the v3 specification.
Our SPDX im- & export service has been designed to simplify the data exchange, especially with Into and out of other services. The idea has been that you might take any tool that supports your use case and provide an SPDX export. This result then may be imported to TrustSource, e.g. you scan code with Fossology, provide an SPDX export of the results and import this data into TrustSource for further processing.
Currently TrustSource SPDX Im- & Export service speaks SPDX v2.0 in XLS, RDF and CSV formats. The service has been designed to take an SPDX file of any specified format and import it into Trustsource or receive a TrustSource structure and export it into a SPDX RDF, XLS or CSV. It interacts with AWS S3 for temporary storage. But the open sourced implementation also will provide a local storage option.
TrustSource CLI:
This will allow to manage the API from your command line.
Comments
0 comments
Article is closed for comments.